


Parallel lines: Generative AI could create 'alternative timelines' for financial markets
Our understanding of financial markets is inherently constrained by historical experience.
The data we have is produced by a single, realised timeline of events that have unfolded. Yet each market cycle, geopolitical event, or policy decision represents just one manifestation of potential outcomes.
This limitation becomes particularly acute when training machine learning (ML) models, which can inadvertently learn from historical artifacts rather than underlying market dynamics.
As complex ML models become more prevalent in investment management, this tendency to overfit to specific historical conditions poses a growing risk to investment outcomes.
Generative AI-based synthetic data is emerging as a potential solution to that challenge.
While generative AI (GenAI) has gained attention primarily for natural language processing, its ability to generate sophisticated synthetic data may prove even more valuable for quantitative investment processes.
By creating data that effectively represents "parallel timelines," this approach can be designed and engineered to provide richer training datasets that preserve crucial market relationships while exploring counterfactual scenarios.
Moving beyond single timeline training
Traditional quantitative models face an inherent limitation. They learn from a single historical sequence of events that led to the present conditions. This creates what we term 'empirical bias'.
The challenge becomes more pronounced with complex machine learning models, whose capacity to learn intricate patterns makes them particularly vulnerable to overfitting on limited historical data.
An alternative approach is to consider counterfactual scenarios; those that might have unfolded if certain, perhaps arbitrary events, decisions or shocks had played out differently.
To illustrate these concepts, consider active international equities portfolios benchmarked to MSCI EAFE.
Figure 1 shows the performance characteristics of multiple portfolios - upside capture, downside capture, and overall relative returns - of various portfolios over the past five years ending on 31st January, 2025.
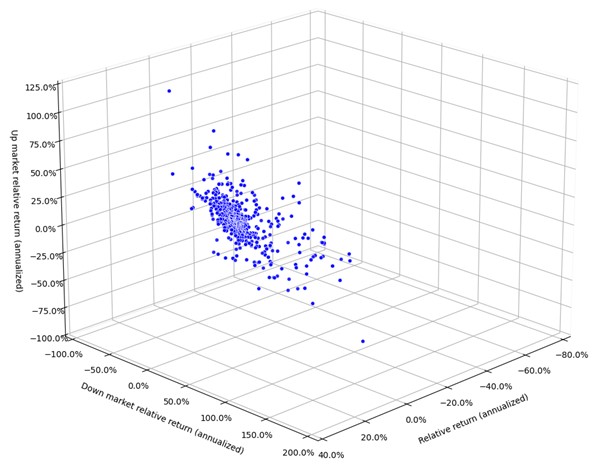
This empirical dataset represents just a small sample of possible portfolios, and an even smaller sample of potential outcomes had events unfolded differently. Traditional approaches to expanding this dataset have significant limitations.
The limitations of traditional synthetic data
Conventional methods of synthetic data generation attempt to address data limitations but often fall short of capturing the complex dynamics of financial markets.
Using our EAFE portfolio example, we can examine how different approaches perform.
Instance-based methods like K-NN and SMOTE extend existing data patterns through local sampling, but remain fundamentally constrained by observed data relationships.
They cannot generate scenarios beyond their training examples, limiting their utility for understanding potential future market conditions.
Traditional synthetic data generation approaches, whether through instance-based methods or density estimation, face fundamental limitations.
While these approaches can extend patterns incrementally, they cannot generate realistic market scenarios that preserve complex inter-relationships while exploring genuinely different market conditions.
This limitation becomes particularly clear when we examine density estimation approaches.
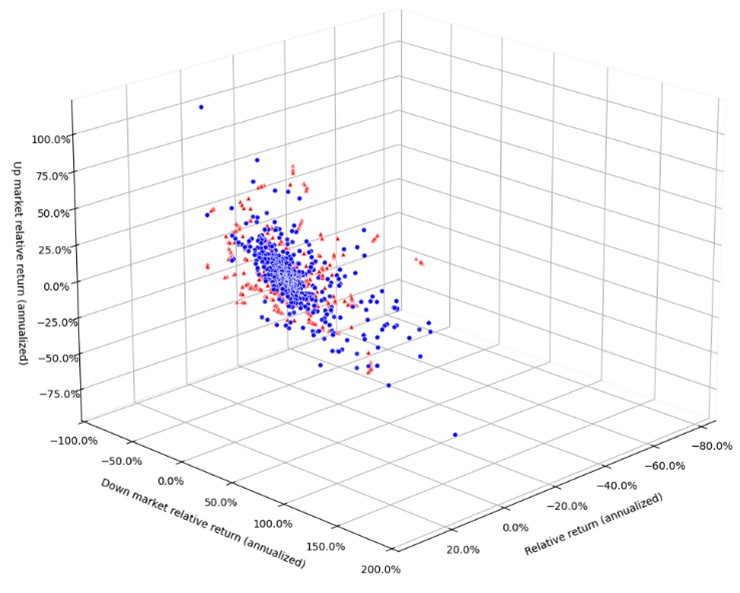
Density estimation approaches like GMM and KDE offer more flexibility in extending data patterns, but still struggle to capture the complex, interconnected dynamics of financial markets.
These methods particularly falter during regime changes, when historical relationships may evolve.
Recent research at City St Georges and the University of Warwick, presented at the NYU ACM International Conference on AI in Finance (ICAIF), demonstrates how GenAI can potentially better approximate the underlying data generating function of markets.
Through neural network architectures, this approach aims to learn conditional distributions while preserving persistent market relationships. This work expands on work on generative adversarial networks (GAN) including CorrGAN, TimeGAN.
This approach to synthetic data generation can be expanded to offer several potential advantages:
- Expanded Training Sets: Realistic augmentation of limited financial datasets
- Scenario Exploration: Generation of plausible market conditions while maintaining persistent relationships
- Tail Event Analysis: Creation of varied but realistic stress scenarios
As illustrated in Figure 3, GenAI synthetic data approaches aim to expand the space of possible portfolio performance characteristics while respecting fundamental market relationships and realistic bounds.
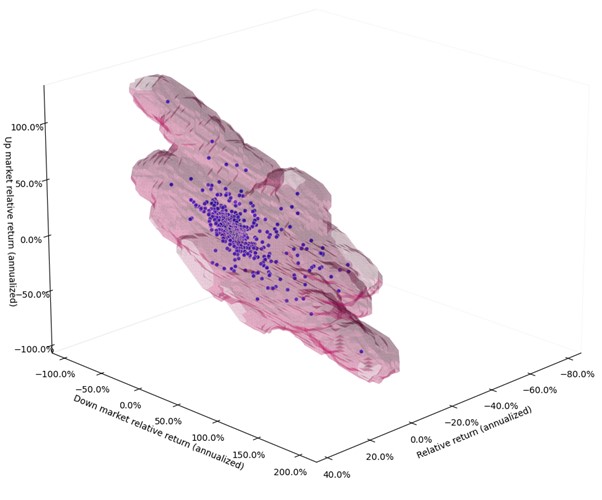
Training better models with GenAI
This provides a richer training environment for machine learning models, potentially reducing their vulnerability to historical artifacts and improving their ability to generalize across market conditions.
For equity selection models, which are particularly susceptible to learning spurious historical patterns, GenAI synthetic data offers three potential benefits:
1 Reduced Overfitting: By training on varied market conditions, models may better distinguish between persistent signals and temporary artifacts
2 Enhanced Tail Risk Management: More diverse scenarios in training data could improve model robustness during market stress
3 Better Generalization: Expanded training data that maintains realistic market relationships may help models adapt to changing conditions
The implementation of effective GenAI synthetic data generation presents its own technical challenges, potentially exceeding the complexity of the investment models themselves.
However, our research suggests that successfully addressing these challenges could significantly improve risk-adjusted returns through more robust model training.
GenAI synthetic data has the potential to provide more powerful, forward-looking insights for investment and risk models.
Through neural network-based architectures, it aims to better approximate the market's data generating function, potentially enabling more accurate representation of future market conditions while preserving persistent inter-relationships.
While this could benefit most investment and risk models, a key reason it represents such an important innovation right now is owing to the increasing adoption of machine learning in investment management and the related risk of overfit.
GenAI synthetic data can generate plausible market scenarios that preserve complex relationships while exploring different conditions. This technology offers a path to more robust investment model.
However, even the most advanced synthetic data cannot compensate for niaive machine learning implementations. There is no safe fix for excessive complexity, opaque models, or weak investment rationales.
Further reading:
Why AI could transform peer-to-peer lending for investors
Preparing for the AI revolution in real estate
Why pension funds must reduce the AI skills gap
The flaw in the data that led corporate bond investors astray
Dan Philps is co-leader of AI research at the Gillmore Centre for Financial Technology at Warwick Business School. Learn more about the new MSc Financial Technology developed by the Centre.
Discover more on Fintech, Finance, and Markets. Subscribe to up to the Core Insights newsletter via email and LinkedIn.
 X
X Facebook
Facebook LinkedIn
LinkedIn YouTube
YouTube Instagram
Instagram Tiktok
Tiktok